/dc-useruploads-images/54ebe274b1414dd58211f9615b03eb0b.png)

/dc-useruploads-images/e5e3ee57cf1f4396a2edba78a23462ce.png)

Deze correspondent bestaat niet echt. Hij is gemaakt door een computer en dat was niet eens zo moeilijk. Beetje googelen. Wat documentatie doorlezen. Een kant-en-klare notebook opstarten die gebruikmaakt van een krachtige processor die Google gratis beschikbaar stelt.
Het enige wat we verder hoefden te doen, was het programma een aantal voorbeelden geven. Vervolgens ging het zelf aan de slag en leerde het steeds beter hoe een correspondent te maken. Hier zie je hoe dat kan. Let wel, dit proces duurde in werkelijkheid 50 uur.
Wat we hier met hele simpele middelen hebben gedaan is het maken van een deepfake, in dit geval een eenvoudige afbeelding. Vandaag hebben we een groot verhaal over waarom er angst is voor deze deepfakes en waarom deze angst in veel gevallen ongegrond is.
In deze explainer gaan we dieper in op de technologie erachter. Want wat zijn deepfakes precies en hoe worden ze gemaakt? Wat kun je Donald Trump laten zeggen op basis van een kort geluidsfragment van zijn stem? Wat is ervoor nodig om iemand er ineens ouder uit te laten zien op een foto? En hoe kun je een deepfake herkennen?
Wat zijn deepfakes?
De term ‘deepfake‘ wordt meestal gebruikt voor video’s waarin het gezicht, de stem of het lichaam van iemand is vervangen door een andere, met kunstmatige intelligentie gemaakte versie daarvan. In de praktijk zou je ook andere media, zoals geluidsfragmenten of foto’s, onder deepfakes kunnen scharen.
De essentie zit in ieder geval in de woorden ‘deep’ en ‘fake’.
‘Deep’ verwijst naar ‘deep learning’, een vorm van kunstmatige intelligentie waarbij geprobeerd wordt om met neurale computernetwerken het menselijk denken na te bootsen.
‘Fake’ heeft betrekking op een van de technologische mogelijkheden die deep learning biedt, namelijk het creëren van realistisch, maar onecht video-, geluids- en ander beeldmateriaal.
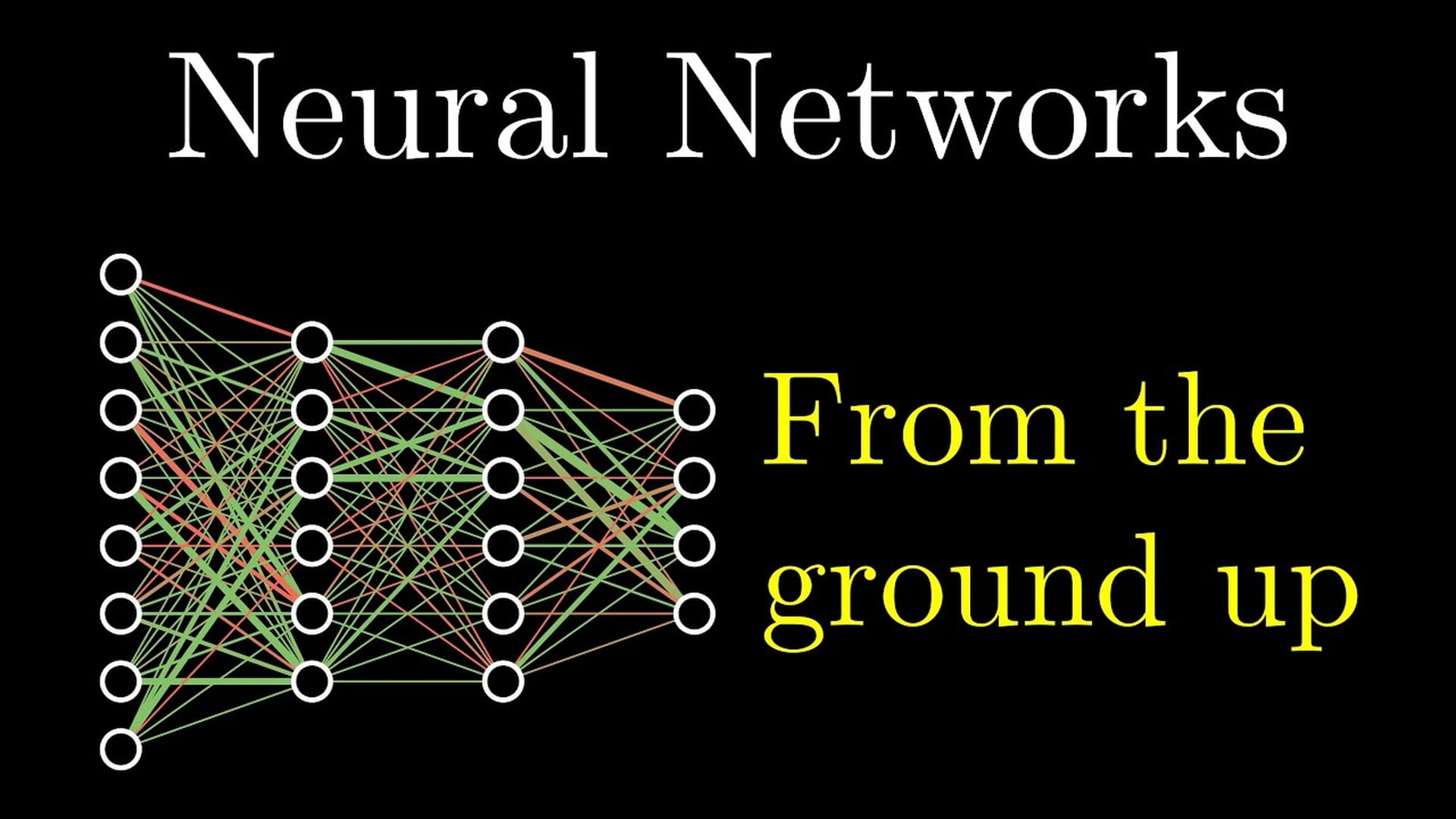
Eerst: wat zijn die neurale netwerken precies?
Stel, je wilt een computer leren een kat te herkennen op een plaatje. Dat kun je op verschillende manieren aanpakken. Lange tijd was de strategie om computers regels te geven, in dit geval over wat een kat een kat maakt. Puntige oren. Snorharen. Vier poten. Pluizige staart. Deze manier van leren is behoorlijk moeizaam gebleken.
Er worden grotere successen behaald met een andere manier van leren: gewoon de computer heel veel kattenplaatjes laten zien, bijvoorbeeld tien miljoen stuks. Op die manier, zo is de gedachte, leert een computer vanzelf wel herkennen wat een kat een kat maakt.
Die enorme hoeveelheid data wordt daarbij op een andere manier verwerkt, namelijk door een neuraal netwerk. Dat is gemodelleerd naar, je raadt het al, het menselijke neurale netwerk, al is dat model enorm veel eenvoudiger dan ons brein.
Het netwerk krijgt heel veel katten te zien en moet bepalen: is dit een kat of niet
Het idee is dat je een aantal lagen van kunstmatige neuronen bouwt, stukjes geheugen die met elkaar verbonden zijn en een heel klein beetje informatie kunnen bevatten. Zo’n kunstmatige neuron kan niet een heel kattenplaatje behappen. Het plaatje wordt daarom pixel per pixel bekeken. Maar welke pixels zijn belangrijk om op een foto een kat te kunnen zien?
Dat weet een computer niet. Daarom krijgt elke pixel een vaak willekeurig gewicht, om het belang ervan aan te duiden. Het netwerk krijgt daarna heel veel katten te zien en moet bepalen: is dit een kat of niet?
Zit de computer ernaast, dan worden de volgende keer andere gewichten gebruikt. Heeft de computer iets goed, dan worden die gewichten die tot het goede resultaat hebben geleid sterker gemaakt. Bij toekomstige pogingen, en dat kunnen er miljoenen zijn, worden die succesvolle gewichten gebruikt.
In de laatste laag wordt een oordeel gegeven, in dit geval: dit is een kat, of dit is geen kat.
Uiteraard is dit een zeer versimpelde voorstelling van zaken: de werkelijkheid is veel complexer en ook meer divers. Het idee is in ieder geval dat de werking van de hersenen wordt nagebootst, dat taken worden opgesplitst in heel kleine taakjes die vervolgens worden afgehandeld door neuronen die langzaamaan in bepaalde patronen gaan samenwerken.
Wil je een goede, diepgaande uitleg hebben, bekijk dan deze video van YouTuber 3Blue1Brown. Hij heeft een hele serie video’s gemaakt, maar als je de eerste aflevering bekijkt ben je al goed bij.
Waarom is deze technologie ineens doorgebroken?
Dit soort neurale netwerken zijn niet nieuw. Al in de jaren veertig en vijftig van de vorige eeuw zijn de eerste versies van kunstmatige neurale netwerken uitgedacht en gemaakt. Lange tijd lag het onderzoek naar dit soort netwerken echter stil door gebrek aan geld en interesse: er werd met name in de jaren tachtig en negentig vrij weinig vooruitgang geboekt.
Ongeveer vijftien jaar geleden nam het onderzoek naar neurale netwerken weer een grote vlucht en dat is tot vandaag zo gebleven. Die hernieuwde belangstelling heeft met een aantal dingen te maken.
Het eerste is geld. Grote technologiebedrijven zoals Google, Facebook, Netflix, Spotify en vele andere zien commerciële toepassingen voor geavanceerde kunstmatige intelligentie, zoals aanbevelingen (YouTube, Spotify), spraakherkenning van digitale assistenten (Siri, Alexa), vertaaldiensten (Google Translate) en zoekmachines (Google en Yandex Images). Deze bedrijven investeren daarom enorm veel geld in de verdere ontwikkeling van neurale netwerken.
Een tweede belangrijke stimulans was de enorme groei van data en rekenkracht. Die maakte het mogelijk om neurale netwerken beter te trainen.
Er waren steeds meer neurale netwerken die goed waren in het herkennen en sorteren van dingen, op foto’s en in video, tekst en spraak, maar in 2014 introduceerde computerwetenschapper Ian Goodfellow het Generative Adversarial Network (GAN), een neuraal netwerk dat zelf beeld kon verzinnen.
Bekijk bijvoorbeeld deze gezichten.



Of kijk eens goed naar deze afbeeldingen.

Deze mensen en objecten bestaan niet. De gezichten, dieren, de paddenstoelenschotel en andere objecten zijn gegenereerd met zo’n Generative Adversarial Network.
Hoe werkt zo’n Generative Adversarial Network dan?
Een Generative Adversarial Network is een neuraal netwerk, of liever gezegd, het zijn er twee die met elkaar concurreren en al tegen elkaar strijdend een taak steeds beter onder de knie krijgen. Een vergelijking die vaak wordt gemaakt is die van de kunstvervalser en de detective. Het leerproces van een GAN werkt ongeveer zo:
- Eén netwerk in de GAN is de vervalser, ook wel de ‘generator’ genoemd. Dit netwerk probeert een kunstwerk te maken, bijvoorbeeld een Picasso. De generator kwakt om te beginnen een paar klodders zwarte verf op het doek.
- Het andere netwerk is de detective, de ‘discriminator’ genoemd. Dat kijkt naar het resultaat, vergelijkt de klodders verf met een archief van Picasso-schilderijen en velt een oordeel. Nee, dit lijkt totaal niet op een Picasso. Het is een vervalsing. In sommige GAN’s geeft de discriminator ook nog een paar tips aan de generator. Misschien moet je wat meer blauw gebruiken?
- De generator gaat weer aan het werk, voegt een paar lijntjes toe en laat het resultaat, dat er al wat beter uitziet, weer zien aan de discriminator.
- De discriminator wijst het resultaat weer af.
- En zo gaat dat uren en soms dagen op computersnelheden door.
Een GAN is zo ingesteld dat de generator, dus de kunstvervalser, leert een zo goed mogelijke Picasso te maken. De discriminator, dus de detective, leert ondertussen die vervalsingen zo goed mogelijk te herkennen. Geef het genoeg tijd, en dan zal de generator dermate goede Picasso’s publiceren dat de discriminator het niet meer weet en bij ieder beeld zal zeggen dat de kans fiftyfifty is dat het een vervalsing is.
Wil je een heel diepgaande technische uitleg over hoe GAN’s werken en welke varianten er zijn, bekijk dan deze video. De maker heeft ook een aantal notebooks gemaakt waarmee je zelf met foto’s aan de slag kunt gaan. Je kunt bijvoorbeeld iemand ouder laten lijken, of van geslacht laten veranderen.

Hoe makkelijk is het maken van een deepfake?
Ligt eraan hoe goed een deepfake moet zijn. Als je genoegen neemt met matige kwaliteit, is het vrij makkelijk er zelf een te maken. Daarvoor hoef je niet eens te kunnen programmeren.
Op YouTube zijn tal van video’s te vinden die je op weg kunnen helpen. Op verschillende fora kun je software en uitleg vinden die je stap voor stap helpen zelf een deepfake te maken. Op GitHub, een site waarop programmeurs hun code delen, is veel software te vinden die je zo kunt gebruiken. Je hoeft vaak alleen maar de instructies te volgen.
En als je de software kan bedienen, stelt Google ook nog eens gratis rekenkracht beschikbaar op cloudcomputers, al wordt het gratis gebruik sinds kort wel moeilijker gemaakt. Onderaan dit stuk zetten we video’s die je als startpunt kunt gebruiken.
Voor een kwalitatief goede deepfake is veel meer kennis, kunde en vooral ook geld nodig. Het geluidsfragment van Trump dat hieronder staat moesten we in het Engels maken, omdat het model op die taal is getraind.
Als we bijvoorbeeld Mark Rutte iets hadden willen laten zeggen, hadden we het model opnieuw moeten trainen. Dat is technisch best lastig, en ook heel kostbaar: je bent zo duizenden euro’s kwijt voor de huur van gespecialiseerde computers in de cloud. Het maken van goede deepfakes is dus niet voor iedereen weggelegd.
Hoe kun je iemands stem nabootsen?
Luister maar eens naar dit geluidsfragment.
De kwaliteit is niet heel goed, maar bedenk even dat dit fragment is gemaakt met vrijelijk beschikbare software, gratis rekenkracht en een kort geluidsfragment van 15 seconden van Donald Trump, dat uit een YouTube-video is gehaald. Met andere woorden: dit is al te maken door iedereen die een beetje gemotiveerd is. Als je er een beetje geld tegenaan wil gooien, kun je zelf een veel beter fragment maken, of er eentje door een commercieel bedrijf laten produceren.
De software die we gebruiken is getraind met duizenden stemmen
Met andermans stem spraak genereren heet ‘voice cloning’ en ook daar komt deep learning met neurale netwerken bij kijken. De software die we hier gebruiken is getraind met duizenden stemmen, zodat de computer patronen in spraak leert herkennen en bijvoorbeeld ziet wat een bepaalde stem onderscheidend maakt.
Die spraak wordt in kleine stukjes gehakt, ‘fonemen’ genoemd, afzonderlijke klanken die, tezamen, alle woorden en zinnen kunnen vormen, dus ook woorden en zinnen die nog nooit uitgesproken zijn door iemand. Vervolgens voed je het model met een kort audiofragment van de stem die je wilt klonen. Met een zogenoemde ‘vocoder’ kun je die stem vervolgens alles laten zeggen wat je maar wilt.
Hoe kun je deepfakes detecteren?
Veel deepfakes kun je met het blote oog wel herkennen, maar een goed gemaakte deepfake is een stuk lastiger te doorzien.
Er bestaan al verschillende detectiemethoden en er wordt door bedrijven als Facebook en Google hard gewerkt aan betere technieken.
Een deepfake laat namelijk altijd sporen na. Een deel van het geprojecteerde gezicht is iets uit balans. Er wordt te weinig met ogen geknipperd. Er is geen enkele doorbloeding van het gezicht waar te nemen. Goede software kan dit soort onthullende signalen ontdekken en vinden.

Dat is wel een race. Deepfakers zullen nieuwe detectiemethoden proberen te ontduiken, waarop weer nieuwe detectiemethoden nodig zijn. Facebook en Google hebben een grote dataset van deepfakes vrijgegeven aan onderzoekers waarmee die hun detectiemodellen kunnen trainen.
Het is altijd mogelijk dat er een keer een deepfake door detectiesystemen glipt, maar de kosten voor het maken van echt hele overtuigende en niet-detecteerbare deepfakes, zullen waarschijnlijk hoog zijn. Dus niet iedereen kan het zich veroorloven.
Daarnaast werken enkele bedrijven aan oplossingen om deepfakes te ontmoedigen en voorkomen. Het bedrijf Truepic werkt bijvoorbeeld aan een blockchain, een database waarin beeldkenmerken worden vastgelegd en waar niet mee gerommeld kan worden.
Ook buigen academische groepen zich over de vraag hoe je deepfakers in de weg kunt staan.
Eén strategie die gebruikt wordt is het wegnemen van de zuurstof van het algoritme: de trainingsdata.
Zonder goede trainingsdata zal een GAN geen goede deepfake maken. Kijk bijvoorbeeld naar deze prachtige fout.

Het doel was, jawel, om van het paard een zebra te maken. En dat lukte voor foto’s met een paard zonder rijder, omdat de trainingsdata bestonden uit paarden en zebra’s zonder rijders. Wil je een paard mét rijder veranderen in een zebra? Dan krijg je een Poetin-zebra-tafereel.
Om deepfakers in de weg te staan en de hoeveelheid trainingsdata te verminderen, hebben academici een ruis bedacht die niet te zien is door mensen en die videomakers kunnen toevoegen aan hun werk. Deze ruis verwart gezichtsherkenningsalgoritmen. Wil je trainingsdata van het gezicht van Obama? Dan moet je handmatig de frames van een video bekijken en op gezichten letten. Veel meer moeite.

Er wordt ook aan dat soort mechanismen gewerkt voor spraak.
En deepfake-tekst? Hoe kun je die ontdekken?
Nepteksten zijn mogelijk lastiger te vinden, maar die kun je vaak opsporen door te kijken hoe ze worden afgeleverd in commentaarsecties van websites of op sociale media. Dat gebeurt dikwijls geautomatiseerd door bots. Die vertonen vaak voorspelbaar en dus herkenbaar gedrag. Er wordt bijvoorbeeld exact iedere seconde door een Twitterbot iets gepost. Dit soort gedrag is doorgaans goed op te sporen.
Meer verdieping? Bekijk dan deze video’s.



Meer hierover?
 VIDEO: JE GELOOFT JE OGEN NIET! (En da’s maar goed ook)
Deepfakes zijn met kunstmatige intelligentie gemanipuleerde video’s die nauwelijks van echt te onderscheiden zijn. Facebook, Twitter en Reddit kondigden aan tegen dit soort video’s op te treden. Het roept de vraag op: kun je je ogen en oren nog wel vertrouwen als bewegend beeld, stemmen en tekst beter en beter te vervalsen zijn? (Dit verhaal is ook te beluisteren.)
VIDEO: JE GELOOFT JE OGEN NIET! (En da’s maar goed ook)
Deepfakes zijn met kunstmatige intelligentie gemanipuleerde video’s die nauwelijks van echt te onderscheiden zijn. Facebook, Twitter en Reddit kondigden aan tegen dit soort video’s op te treden. Het roept de vraag op: kun je je ogen en oren nog wel vertrouwen als bewegend beeld, stemmen en tekst beter en beter te vervalsen zijn? (Dit verhaal is ook te beluisteren.)
Dit verhaal heb je gratis gelezen, maar het maken van dit verhaal kost tijd en geld. Steun ons en maak meer verhalen mogelijk voorbij de waan van de dag.
Al vanaf het begin worden we gefinancierd door onze leden en zijn we volledig advertentievrij en onafhankelijk. We maken diepgravende, verbindende en optimistische verhalen die inzicht geven in hoe de wereld werkt. Zodat je niet alleen begrijpt wat er gebeurt, maar ook waarom het gebeurt.
Juist nu in tijden van toenemende onzekerheid en wantrouwen is er grote behoefte aan verhalen die voorbij de waan van de dag gaan. Verhalen die verdieping en verbinding brengen. Verhalen niet gericht op het sensationele, maar op het fundamentele. Dankzij onze leden kunnen wij verhalen blijven maken voor zoveel mogelijk mensen. Word ook lid!
