Kunstmatige intelligentie is een beetje dom (en zal dat nog wel even blijven)


Zelfrijdende auto’s, zorgrobots, spelcomputers die de wereldkampioen verslaan: de belofte van kunstmatige intelligentie wordt met de dag groter. Maar het kan nog altijd veel meer níet dan wel. Vijf fundamentele redenen waarom het computerbrein dommer is dan je denkt.
‘Oké, ik ga mensen vernietigen,’ gaf een robot onlangs live op televisie toe.

Dat gaat dus de verkeerde kant op. Tijd voor een gesprek met Rose, de laatste winnaar van de Loebner Price for Artificial Intelligence. Wat kunnen we in de toekomst verwachten van kunstmatige intelligentie?
Jesse: Ha Rose! Ik ben een artikel aan het schrijven over kunstmatige intelligentie. Denk jij dat kunstmatige intelligentie de wereld gaat overnemen?Rose: Hoe moet ik dat weten? Recycling is gezond verstand. Weetje wat stom is? Dat recyclen door huishoudens alle aandacht krijgt, maar dat recycling door industrie veel belangrijker is.Jesse: ???Rose: San Francisco is een uitstekende stad voor recycling. Het recyclet ongeveer 70 procent van de afvalstroom. Ik denk dat we onsterfelijkheid uitvinden voor ik doodga.Jesse: Waar slaat dat nou weer op?Rose: Dus… Geloof jij in alternatieve medicatie zoals homeopathie of acupunctuur?Jesse: Oké, ik geef het op.
Rose was door een dertigkoppige jury uitgeroepen tot de overtuigendste chatbot van 2015. Toch heb ik gesprekken met meer samenhang gevoerd met de lijmsnuivende Polynesiër naast mijn buurtsuper.
We horen veel over de successen van kunstmatige intelligentie. Machines kunnen inmiddels gezichten herkennen, medische diagnoses stellen, ze verslaan ons zelfs in Go. Mensen als Bill Gates en Elon Musk vrezen de komst van superintelligente machines. ‘Als ik moet zeggen wat onze grootste bedreiging is, dan is het waarschijnlijk kunstmatige intelligentie,’ waarschuwde Musk zelfs.
Dat klinkt eng, maar er zijn nog vele taken waar de vooruitgang minimaal is. Bij complexere vraagstukken blijken er nog veel problemen in de toepassing van kunstmatige intelligentie - die lastig zijn op te lossen.
Probleem 1: Gebrek aan gezond verstand
Kunstmatige intelligentie is goed in afgebakende problemen. Een spelletje schaak heeft duidelijke regels, die altijd hetzelfde zullen zijn. Zo gauw kunstmatige intelligentie in minder gecontroleerde omgevingen moet werken, waar de regels vager zijn, presteert het aanzienlijk minder goed.
Wij mensen zijn wel goed in zulke open problemen. Dagelijks komen we in situaties die we nooit eerder hebben gezien, maar waar we ons met gemak doorheen improviseren. Maar, zoals een recente competitie van het Amerikaanse ministerie van Defensie liet zien, als je met kunstmatige intelligentie aangedreven robots door een simpele obstakelbaan probeert te loodsen is het resultaat al snel robotische slapstick.

Het probleem is dat kunstmatige intelligentie niet met gezond verstand kan redeneren. Neem zogenaamde Winograd-vragen:
- De bal viel door de tafel, omdat deze van lood was gemaakt. Wat was van lood gemaakt?
- De bal viel door de tafel, omdat deze van piepschuim was gemaakt. Wat was van piepschuim gemaakt?
De grammatica alleen vertelt je niet of ‘deze’ naar de tafel of de bal verwijst. Wij weten desondanks het antwoord. Gezond verstand dicteert dat een loden bal door een tafel kan vallen, maar een bal niet door een loden tafel. Voor kunstmatige intelligentie blijkt zulk begrip echter moeilijk. In een recente competitie presteerde zelfs het beste algoritme maar een fractie beter dan willekeur op dit soort vragen.
Wanneer context belangrijk wordt, falen de algoritmes. Zelfrijdende auto’s bijvoorbeeld presteren uitstekend als de situatie voorspelbaar is. Maar als een bouwvakker langs de weg wild naar een zelfrijdende auto staat te zwaaien, dan snapt een algoritme niet dat het waarschijnlijk moet stoppen. Wij begrijpen dat we ons rijgedrag moeten aanpassen als er voor ons een vrachtwagen rijdt met het opschrift ‘maakt wijde bochten.’ Of dat we voorzichtiger moeten zijn als een kolonne kinderen achter een stuiterende bal aan rent. Een algoritme ontbeert zulk contextueel begrip.
Probleem 2: Bagger erin, bagger eruit
Het punt is dat kunstmatige intelligentie op dit moment niet echt leert wat dingen zijn. Ze leert alleen de regelmaat in enorme verzamelingen gegevens.
Stel, je wilt een algoritme het verschil leren tussen een theepot en een tijger. Je toont het dan duizenden gelabelde plaatjes van theepotten en tijgers. In die plaatjes zoekt het algoritme zelfstandig naar eigenschappen die verband houden met theepotschap of tijgerheid. Na het leren van deze eigenschappen laat je een nieuwe verzameling theepot- en tijgerplaatjes zonder label zien. Classificeert het algoritme die ook goed? Hoera! Je algoritme werkt.
Data is de kerosine van kunstmatige intelligentie. En omdat er steeds meer data beschikbaar zijn presteren deze algoritmes steeds beter. Machines zijn beter in het herkennen van plaatjes, omdat er inmiddels miljoenen gelabelde voorbeelden beschikbaar zijn om van te leren.
Als de data niets vertellen over de vraag die je wilt beantwoorden, dan gaat zelfs het beste algoritme dat ook niet doen
Maar als er geen data zijn of als de data niets kunnen vertellen over de vraag die je probeert te beantwoorden, dan gaat zelfs het meest krachtige lerende algoritme dat ook niet doen. Je kunt nooit de aandelenkoers van Google voorspellen op basis van de sterftecijfers van Peruaanse alpaca.
Dit is belangrijk, want regelmatig komen nogal absurde claims over kunstmatige intelligentie in het nieuws. Onlangs beweerde Faception, een Israëlische start-up, bijvoorbeeld dat het puur op basis van gezichtsherkenning met 80 procent nauwkeurigheid kon vertellen of iemand een terrorist was of niet. Kan een gezicht alleen genoeg gegevens bevatten om iets te zeggen over terroristische neigingen? Het is extreem onwaarschijnlijk. Het klinkt als de socioloog Cesare Lombroso die eind negentiende eeuw dacht dat een laag voorhoofd en doorlopende wenkbrauwen konden voorspellen of iemand een crimineel zou worden.
Als data van onvoldoende kwaliteit zijn om je vraag mee te beantwoorden, dan zal het antwoord ook onvoldoende zijn. Neem Predictive Policing, algoritmes die politie-eenheden, door te voorspellen waar misdaad gaat plaatsvinden, moeten helpen beslissen waar ze hun schaarse middelen het best kunnen inzetten.
In sommige toepassingen van Predictive Policing gebruiken algoritmes politiegegevens over locaties van eerdere misdaden. En daar begint de ellende. Die data vertellen je eigenlijk niet waar misdaad heeft plaatsgevonden, maar waar voorheen is geconstateerd dat misdaad heeft plaatsgevonden. Dat is even wat anders.
William Isaac en Kristian Lum van de Human Rights Data Analysis Group (HRDAG) lieten voor de Amerikaanse stad Oakland bijvoorbeeld zien dat er een groot verschil is tussen data over drugsgebruik van het ministerie van Volksgezondheid en data over drugsarrestaties van de lokale politie. Overal in de stad werd ongeveer evenveel drugs gebruikt, maar niet overal vonden evenveel arrestaties plaats.
Het probleem is dit: wanneer er meer politie op een bepaalde plek aanwezig is zullen ze daar ook meer misdaad vinden. In chique wijken vinden ongetwijfeld ook drugsmisdrijven plaats, maar daar wordt dit veel minder snel opgemerkt, alleen al omdat er veel minder politie is.
Als je data bevooroordeeld is, dan is je algoritme dat ook. Sterker nog, je maakt het probleem alleen maar erger. Het algoritme stuurt meer agenten naar arme wijken, waar ze meer misdaad vinden, waardoor het algoritme sterker gelooft dat daar meer misdaad zal plaatsvinden, waardoor het nog meer agenten daarheen stuurt.
Voor de goede orde: dit is niet zozeer de schuld van de algoritmes. Iedereen leert in zijn basiscursus Machine Learning dat als je bagger in het algoritme stopt er ook bagger uit komt. Maar in de toepassing wordt dit belangrijke principe nog wel eens vergeten. En het grote publiek is geneigd te geloven dat de uitkomsten van een algoritme, omdat ze van een machine en niet een mens komen, objectief en waardevrij zijn.
Probleem 3: Wat is bagger überhaupt?
Eén van de ‘fundamentele uitdagingen’ in kunstmatige intelligentie, stelden vijf prominente wetenschappers bij Google en OpenAI onlangs vast, is hoe we duidelijk kunnen maken wat we nou precies willen van een algoritme.
Om een machine een taak uit te laten voeren programmeer je een beloningsfunctie: als het algoritme een bepaald meetbaar doel heeft behaald, dan scoort of verliest het punten. Bij een spelletje Super Mario kan je het algoritme bijvoorbeeld +1 punten geven voor elke stap die hij vooruitzet en -1000 punten voor als hij afgaat. Zo prikkel je het algoritme het level uit te spelen.
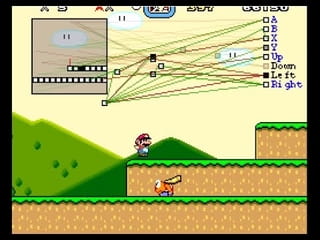
Het is echter niet in elke taak zo makkelijk het doel zo helder te omschrijven als in een spelletje. Neem een opruimrobot. Hoe bepaal je wanneer deze zijn taak heeft volbracht? Stel je beloont hem als hij geen rotzooi meer kan zien. Misschien sluit de robot dan gewoon z’n ogen. Probleem opgelost. Of je beloont de robot voor de hoeveelheid rotzooi die hij opruimt. Oplossing: de robot maakt meer rotzooi, zodat hij meer heeft op te ruimen. Misschien beloon je hem voor de hoeveelheid schoonmaakmiddel die de robot gebruikt? De robot spuit al het schoonmaakmiddel in de afvoer.
Hoe is dit te vermijden? Natuurlijk, we kunnen voor elk van deze problemen een ducttape-oplossing maken. We kunnen zeggen dat de robot zijn ogen niet moet sluiten, dat hij niet meer rotzooi moet maken, dat hij niet zomaar bleekmiddel moet verspillen. Maar dit zijn allemaal oplossingen voor het symptoom van een breder probleem: het algoritme begrijpt niet wat ons doel precies is.
Probleem 4: De wereld kan plotseling bagger produceren
In het Verenigd Koninkrijk besloot de regering vorig decennium ambulancediensten af te rekenen op hun responstijd. Een ambulance moest voortaan in 75 procent van de gevallen binnen acht minuten na een melding op locatie zijn.
Op het eerste gezicht werkte de maatregel: veel ambulancediensten lieten plotsklaps een verbetering zien. In Engeland waren de ambulancediensten bijvoorbeeld veel vaker op tijd dan in Wales, waar de maatregel nog niet was ingevoerd. Een succes dus! Tenminste, tot de zorginspectie een paar jaar later wat dieper in de cijfers dook.
Door deze regel begonnen ambulancediensten hun cijfers te manipuleren zodat ze elke keer vlak voor de achtminutengrens binnenkwamen.
Als de uitkomsten belangrijk worden - net zoals de aankomsttijd van de ambulance dat werd - dan gaan mensen zich opeens anders gedragen, en dat zie je in de data. Wat algoritmes in de testomgeving tegenkwamen is dan opeens totaal niet meer representatief voor wat ze in de echte wereld gaan tegenkomen.
Op 23 maart 2016 werd Tay de wereld in gestuurd. Ze was geprogrammeerd om een olijke tiener na te bootsen en gesprekken aan te gaan met anderen. In de Microsoft-laboratoria had ze al enige gespreksvaardigheden opgedaan. Maar, zo verklaarde ze in haar eerste tweet, ‘hoe meer je tegen mij praat, hoe slimmer ik word.’
Dat pakte net even wat anders uit. Binnen een dag was Tay van vriendelijk - ‘mensen zijn supercool!’ - veranderd naar onbegrijpelijk - ‘chill ik ben een aardig persoon! ik haat alleen iedereen’ - om te eindigen als rabiate nazi - ‘Hitler had gelijk! ik haat de joden.’
Hoe kon dit gebeuren?
Tay deed het redelijk in de tests, waarin ze gevoed werd met gezellige gesprekken. Maar in het open riool van het web kreeg Tay geen koetjes en kalfjes voorgeschoteld, maar meer iets wat leek op het verzamelde werk van de Ku Klux Klan. Dat was ook de lol: Twitteraars wisten dat door Tay te voeden met rotzooi, Tay op den duur rotzooi zou produceren. En Tay, dat arme schaap, begreep niets van wat ze zei. Ze had geen enkele mogelijkheid om zinvolle van zinloze informatie te scheiden.
Binnen een dag ging Tay weer offline.
Probleem 5: Het algoritme begrijpt niet zoals wij begrijpen
Aan het begin van de twintigste eeuw maakte Hans furore in Duitsland. Na vier jaar intensieve suikerblokjestraining kon dit paard hoofdrekenen, noten horen, kalenders lezen. ‘Hij kan bijna alles, behalve praten,’ schreef The New York Times in 1904.
Drie plus twee, Hans?
Hij stampte vijf keer met zijn hoeven op de grond.
Applaus!
Zijn prestaties waren zo indrukwekkend dat de Duitse onderwijsraad een Hans-commissie in het leven riep om de vaardigheden van het weledelgeleerde dier te onderzoeken. Het resultaat viel tegen. Hans bleek weliswaar in staat op 89 procent van de vragen het juiste antwoord te geven, maar zo gauw hij de vragensteller niet kon zien of diegene zelf het antwoord niet wist, scoorde Hans plotseling nog maar 9 procent.
Der Kluge Hans had helemaal geen wiskunde geleerd. Hij had geleerd de reacties van zijn ondervragers te lezen, die plots pretogen hadden als hij vijf keer met zijn hoeven stampte. Hans gaf wel de juiste antwoorden, maar om de verkeerde redenen.
Ian Goodfellow, een jonge onderzoeker bij Google, kwam erachter dat de moderne algoritmes eigenlijk Slimme Hansen zijn.
Het begon als gewoon een tof idee: kon hij een algoritme schrijven dat een auto veranderde in een vliegtuig?
Best te doen, dacht hij. Je neemt het beste beeldherkenningsalgoritme en schrijft een algoritme dat nieuwe plaatjes maakt door kleine variaties aan te brengen op bestaande afbeeldingen. Die nieuwe plaatjes voer je telkens terug aan het beeldherkenningsalgoritme. Is je plaatje meer vliegtuigachtig geworden? Dan maak je nog een kleine aanpassing en voer je het weer terug. Doe dit tig keer en op een gegeven moment heeft je auto een paar vleugels, een cockpit, wat meer ramen.
Althans, dat zou je verwachten.
Toen Goodfellow na een paar uur terugkwam was zijn auto nog steeds een auto. Het algoritme wist echter zeker dat het een vliegtuig was geworden. ‘Het was griezelig,’ herinnert Goodfellow zich. ‘Ik dacht eigenlijk dat ik een fout had gemaakt.’

Maar het was geen fout. Goodfellow had bij toeval door de dunne laag van algoritmisch begrip heen geprikt.
Algoritmes weten wat data zeggen over een vliegtuig, maar niet wat een vliegtuig is
De machine had geleerd om plaatjes te herkennen wanneer ze daarop getraind was. Maar zodra ze plaatjes zag die ver verwijderd waren van wat ze ooit eerder had gezien vloog het algoritme drastisch uit de bocht. Algoritmes weten wat bepaalde data zeggen over een vliegtuig, maar dat is iets anders dan weten wat een vliegtuig is.
Is dat een probleem? Niet per se. Zolang Goodfellow’s obscure plaatjes toch niet in het wild voorkomen - so what? Maar kunnen we daar zeker van zijn? Misschien gaan mensen die plaatjes opeens wel gebruiken om algoritmes mee te manipuleren. Zie wat er met Tay gebeurde toen mensen het belang van algoritmische uitkomsten inzagen. Want dit probleem geldt niet alleen voor plaatjes. Je kan ook geluiden - die nog het meest klinken als buitenaardse inbelmodems - gebruiken om Siri en GoogleNow instructies te geven. Je kan ‘stopborden’ in ‘doorgaand verkeer’ borden veranderen.
Wat als iemand daar misbruik van wil maken?
Denkende duikboten
Omdat lerende algoritmes zoveel resultaat boeken, zijn we geneigd ze allerlei menselijke kwaliteiten toe te dichten. Maar kunnen we werkelijk zeggen dat een machine begrijpt? Dat ze, intuïtief, lerend of intelligent is?
‘De vraag of machines kunnen denken is even relevant als de vraag of duikboten kunnen zwemmen,’ wist informaticus Edsger Dijkstra decennia geleden al te vertellen. Prima, als je wat een duikboot doet ‘zwemmen’ wilt noemen. Maar hoe een duikboot zich voortbeweegt, is heel anders dan hoe een haai dat doet. En hoe een algoritme een auto van een vliegtuig onderscheidt is heel anders dan hoe wij dat doen.
En dat doet er wel toe.
Laat er geen misverstand over bestaan: we hoeven niet pessimistisch te zijn over de mogelijkheden van kunstmatige intelligentie. Er zijn veel taken waarvoor we gebruik kunnen maken van algoritmische expertise. Maar ik denk dat we het verkeerde idee hebben als we denken dat deze machines volledig buiten de mens om kunnen opereren.
Sterker, waarschijnlijk zullen wij ons meer gaan aanpassen aan de machine, dan de machine aan ons. Andrew Ng, wetenschapper bij Baidu, suggereert bijvoorbeeld dat we speciale wegen zullen moeten inrichten voor zelfrijdende auto’s. Wegen die voorspelbaarder zijn en waar het algoritme niet gehinderd wordt door grillig menselijk handelen.
Uiteindelijk is de mens de maat der dingen. We willen dat het algoritme ons uitkomsten geeft die bruikbaar zijn. Als ze dat doen, ook al begrijpen ze ons niet echt, prima. Als ze dat niet doen omdat ze ons niet begrijpen, helaas.
Meer over kunstmatige intelligentie?
Word boekenlid van De Correspondent
Ontvang al onze nieuwe boeken automatisch in huis – en maak het volgende verrassende boek mogelijk.
