Dit kaartje laat zien waarom we niet zo hard van stapel moeten lopen met kunstmatige intelligentie


Volgens OpenAI en Google kan kunstmatige intelligentie de hele mensheid ten goede komen. Maar uit onderzoek blijkt hoe eenzijdig en beperkt de meeste data zijn waarmee AI is getraind. Volgens onderzoeker Balázs Bodó is dat reden om op de grote rode pauzeknop te drukken.
Kijk eens naar dit kaartje. We zien een opgeblazen Amerika en een piepklein Afrika.
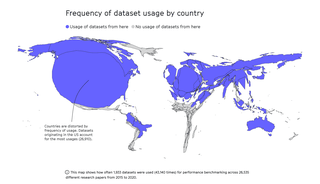
De kaart reflecteert waar de meeste data vandaan komen die gebruikt worden voor kunstmatige-intelligentieonderzoek. Denk aan onderzoek naar taal, plaatjes en gezichten, en hoe een computer die kan herkennen en produceren. Zulk onderzoek vormt de basis van de gehypete programma’s ChatGPT en DALL-E.
Het kaartje draait om zogenoemde benchmark datasets: een gouden standaard die wetenschappers wereldwijd gebruiken om te toetsen hoe goed hun modellen en algoritmen tekst, spraak, objecten en mensen weten te herkennen en te genereren.
Cruciaal bij kunstmatige intelligentie (AI) is waarmee je haar traint. Welke data voer je de machine? Het kaartje hierboven laat zien dat meer dan 60 procent van de gebruikte benchmark datasets uit de Verenigde Staten komt. Er zijn nauwelijks data uit Zuid-Amerika, nagenoeg geen data uit Afrika. Data uit Rusland: verwaarloosbaar.
Wat je bovendien niet op het kaartje ziet is dat slechts twaalf instituten en bedrijven – waarvan er twee niet Amerikaans zijn – de datasets produceren die in meer dan 50 procent van het onderzoek worden gebruikt.* De top drie bestaat uit Princeton, Stanford en Microsoft.
Met andere woorden: een van de belangrijkste technologieën van vandaag, een technologie die de samenleving volgens velen fundamenteel zal veranderen en die draait om getrainde data, wordt voor een groot deel gestut door data uit het land waar mayonaise op een frietje tot scheve ogen leidt.
Als een machine culturele, maatschappelijke en politieke beslissingen neemt
Ik spreek over de kaart en waar die voor staat met Balázs Bodó, een onderzoeker aan de Universiteit van Amsterdam. Ik ken hem als een originele, scherpe denker over digitalisering, en sloeg aan op een tweet van hem. Volgens Bodó toont de kaart wat er op fundamenteel niveau mis is met kunstmatige intelligentie.
Hij wijst erop dat AI nu al wordt ingezet ‘in het hart van onze samenleving’. Om ons nieuws en muziek aan te raden, om ons relevante informatie te geven en aan bepaalde informatie prioriteit te geven. Ze wordt gebruikt om gezichten te classificeren, om fraudeurs te detecteren, om spiekende studenten op examens te identificeren.
‘We vragen deze machines om culturele, maatschappelijke en politieke beslissingen te nemen’, zegt Bodó, ‘die normaal gesproken door goed getrainde en gespecialiseerde individuen worden genomen, zoals journalisten, ambtenaren en economen.’
Los van de vraag hoe wenselijk dat is – zeer onwenselijk als je het aan Bodó vraagt – zijn die machines dus ook nog eens eenzijdig getraind, grotendeels met de data uit één land.
AI produceert alleen wat ze leert
Waarom is dat zorgwekkend? ‘AI-systemen zien de wereld door de data waarmee ze zijn gevoed’, zegt Bodó. ‘En ieder systeem of elke institutie – of het nou een school is, De Correspondent of kunstmatige intelligentie – kijkt niet alleen op een bepaalde manier naar de wereld, ze reproduceren die wereld ook. Met kunstmatige intelligentie gebeurt dat door de teksten, beelden, keuzes en aanbevelingen die ze produceert.’
En dat gaat ook weleens mis. De geschiedenis van AI kent veel pijnlijke voorbeelden van machines die door een verkeerd datadieet verkeerde dingen deden. Taalmodellen zoals GPT-3 blijken bijvoorbeeld naar stereotypes te neigen en moslims met geweld te associëren.* Eerder deze maand werd een AI van seriepersonage Jerry Seinfeld stilgelegd omdat ze transfobe dingen uitkraamde.* Afgelopen december bleek de antispieksoftware van de Vrij Universiteit een zwarte studente te benadelen.* Een paar jaar geleden classificeerde Google foto’s van zwarte mensen automatisch als gorilla’s.*
Bodó vergelijkt het met het opvoeden van je kind. ‘Als jouw kind niet is blootgesteld aan een diversiteit aan informatie over de wereld, dan zal het die diversiteit ook niet reproduceren. Dus als jij je kind niet leert om aardig te zijn, of het niet leert dat er landen zijn waar het recht om wapens te dragen geen onderdeel is van de grondwet, of het niet leert dat de VS niet het belangrijkste land ter wereld is – dan zal het kind ook niet in staat zijn om dat te reproduceren.’

Het gaat Bodó niet alleen specifiek om de VS, want ‘wat zou je ervan vinden als wij AI zouden gebruiken die getraind is op de cultuur, de politiek, de economie en de maatschappelijke verhoudingen van China? Of Rusland? Of Iran?’ Maar het gaat hem ook wél specifiek om de VS.
Wil je AI die getraind is op de sociale en raciale verhoudingen uit de Verenigde Staten invloed laten hebben op het Nederlandse openbaar bestuur en de verzorgingsstaat?
Volgens de onderzoeker – die jarenlang werkte aan de Stanford- en Harvard-universiteiten – staat de Amerikaanse samenleving net zo ver af van de Nederlandse als de Russische. ‘Het is een westers land dat op geen enkel ander westers land lijkt. Waar mensen naar de supermarkt gaan om een pistool te kopen. Waar abortus in veel staten wordt verboden, omdat ze daar liever een fundamentalistische interpretatie van de Bijbel volgen. Waar maar twee grote politieke partijen bestaan – en waarvan de linkse partij in veel andere landen gezien zal worden als heel erg rechts.’
Het is een land waar fundamenteel anders wordt gedacht over zaken als discriminatie, seksualiteit, vrijheid van meningsuiting. ‘Wil je dat onze lokale regels, wetten, normen en cultuur daardoor worden beïnvloed? Wil je in het pluralistische Nederlandse politieke systeem kunstmatige intelligentie gebruiken die getraind is op het Amerikaanse tweepartijensysteem? Wil je een gezondheidszorg-AI gebruiken die is getraind in het Amerikaanse gezondheidszorgsysteem, zonder universele dekking? Wil je AI die getraind is op de sociale en raciale verhoudingen uit de VS invloed laten hebben op het Nederlandse openbaar bestuur en de verzorgingsstaat?’
Retorische vragen waar Bodó een weinig omfloerst antwoord op heeft:
‘Fuck no.’
Testen voor gebruik
Bodó gaat nog een stap verder. Hij vindt de kaart een reden om helemaal te stoppen met kunstmatige intelligentie, of om in ieder geval op een grote rode pauzeknop te drukken.
De technologie wordt nu op veel plekken ingezet zonder er noemenswaardig over na te denken, zegt Bodó. Waarom ligt die lat zo laag? Met eten of medicijnen zijn we veel voorzichtiger, zegt de onderzoeker. ‘Voordat een farmaceutisch molecuul is toegestaan moet het intensief getest worden, op kinderen, op volwassenen, op mensen met verschillende aandoeningen. Dat kost miljoenen. En pas als we de risico’s en de voordelen begrijpen, kunnen we een beslissing nemen.’
Maar we zijn massaal gevallen voor de grootse beloften van deze technologie. OpenAI, het bedrijf achter ChatGPT, zegt opgericht te zijn om ervoor te zorgen dat kunstmatige intelligentie ‘de hele mensheid ten goede komt’.* Google zegt dat AI ‘people, businesses and communities’ helpt om hun ‘potentieel te ontsluiten’ en nieuwe ‘mogelijkheden biedt’ die ‘miljarden levens’ kunnen verbeteren.*
Alleen: waar zijn de bewijzen? Die zijn er niet. Sterker nog: deze kaart, zegt Bodó, is juist een bewijs dat de technologie niet goed genoeg is getraind om al die beloften te vervullen.

Vergelijk het bijvoorbeeld eens met een hypothetisch sollicitatiegesprek met een nieuwe hoofdredacteur van De Correspondent, zegt hij.
‘Die sollicitant zegt: ik ben de beste hoofdredacteur vindbaar en ik zorg ervoor dat De Correspondent de beste journalistiek ooit maakt. Je valt voor deze mooie woorden. Maar vervolgens blijkt dat hij maar nét z’n opleiding journalistiek heeft afgerond, dat al z’n geschreven stukken zeer middelmatig zijn en dat hij nog nooit ergens hoofdredacteur is geweest. Die neem je dus niet aan.’
Zo is kunstmatige intelligentie aantoonbaar verkeerd getraind, kan ze discrimineren, heeft ze vooroordelen en maakt ze vreselijke fouten, zegt Bodó. En de grootse voordelen? Die bestaan vooral uit mooie woorden. ‘Maar in de toekomst wordt het fantastisch, hoor je dan. Waarom accepteren we dat? En zeggen we niet gewoon: het is bullshit?’

Meer lezen?
Een avond over het mbo
Theatertour Karim AmgharKarim Amghar bespreekt met verschillende experts hoe we het mbo – het Meest Belangrijke Onderwijs – meer kunnen waarderen. Kom je ook?
