AI is nog lang geen wondermiddel – zeker niet in het ziekenhuis


Tumoren ontdekken, nieuwe medicijnen ontwikkelen – beloftes genoeg over wat kunstmatige intelligentie kan betekenen voor de medische wereld. Maar voordat je zulk belangrijk werk kunt overlaten aan technologie, moet je precies snappen hoe die werkt. En zover zijn we nog lang niet.
AI maakt het werk van radiologen overbodig. AI zorgt ervoor dat medicijnen sneller op de markt komen.* AI gaat het leven van patiënten fundamenteel veranderen. AI zal een oplossing zijn voor het nijpende tekort in de zorg.*
Er is veel te lezen, te kijken en te luisteren over wat kunstmatige intelligentie allemaal ‘zal’ of ‘gaat’ veranderen. Afgaande op de berichtgeving staan ons meerdere revoluties te wachten – in de zorg, het onderwijs, de journalistiek, de landbouw.
Dit soort berichten wekken de indruk dat de technologie een gegeven is en kunstmatige intelligentie klaar is om de boel flink te disrupten. Dat deze revolutionaire software trappelend op de plank ligt en het slechts de vraag is wanneer ze geïmplementeerd wordt, en dan verandert alles.
Was het maar zo simpel. De realiteit is dat er vooral veel onderzocht, geëxperimenteerd en geprobeerd wordt. Hoe de technologie uit zal pakken, en wat het uiteindelijk gaat veranderen, is onderwerp van studie, en nog ongewis. Ja, er zijn een aantal technische doorbraken geweest, en ja, sommige daarvan zijn beloftevol, maar dat rechtvaardigt de sterke taal over wat het ‘zal’ of ‘gaat’ veranderen niet.
Leerzamer is het om te luisteren naar onderzoekers die onderzoeken in plaats van speculeren.
Berichtgeving en praktijk liggen uit elkaar
Dieuwertje Luitse is promovenda aan de Universiteit van Amsterdam en doet onderzoek naar kunstmatige intelligentie in de gezondheidszorg. Ze kijkt daarbij naar wat ze de ‘machine learning-pijplijn’ noemt: de verschillende stappen in het productieproces van een AI-toepassing.
Want zo’n AI-toepassing komt niet panklaar uit een lab rollen; die komt in verschillende fasen tot stand: van het verzamelen van de juiste data tot het evalueren van die data, en van het trainen van een AI-model op die dataset tot het testen van dat model om te kijken of het geschikt is om toe te passen in een ziekenhuis.

Het onderzoek van Luitse richt zich op de intensive care.* Zoals in veel delen van de gezondheidszorg wordt er op de onderzoeksafdelingen van ic’s druk geëxperimenteerd met kunstmatige intelligentie. Bijvoorbeeld om mogelijke bloedingen bij patiënten die net geopereerd zijn te kunnen voorspellen, zodat artsen aan de hand daarvan op tijd de juiste medicatie kunnen toedienen en mogelijk de bloeding daarmee voorkomen.*
Het is een soort kunstmatige intelligentie die we eigenlijk nog niet goed doorgronden – laat staan dat we weten of ze haar beloften zal waarmaken
Het valt de jonge onderzoeker, die nog aan het begin van haar promotieonderzoek staat, op hoe ver de berichtgeving over AI en de AI-praktijk in het ziekenhuis uit elkaar liggen.
‘Er worden grote woorden gesproken over wat AI allemaal kan betekenen voor verschillende beroepsgroepen, voor de samenleving en zelfs voor de gehele mensheid’, zegt ze. ‘Alles wordt daarbij op één hoop gegooid – de AI-hoop. Maar in het ziekenhuis worden totaal andere toepassingen gebruikt dan ChatGPT of DALL-E. Het is een soort kunstmatige intelligentie die we eigenlijk nog niet goed doorgronden – hoe die tot stand komt, wat daarbij komt kijken en wie daarbij betrokken zijn. Laat staan dat we weten of ze haar beloften zal waarmaken.’
Zuivere datasets, betrouwbare beoordeling
Door kunstmatige intelligentie niet als een panklare technologie te benaderen maar als een productiepijplijn, probeert Luitse in kaart te brengen wat er allemaal komt kijken bij de totstandkoming van die technologie.
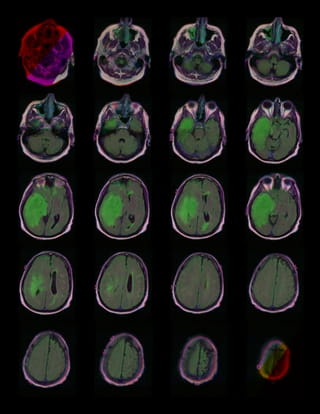
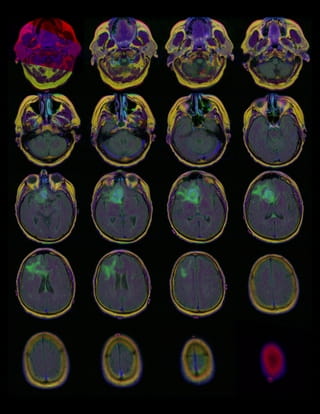
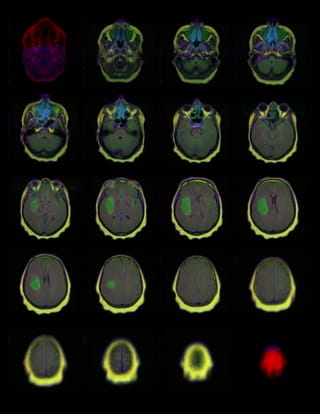
Neem als voorbeeld een tumor in de hersenen die nog niet met het blote oog is te zien. Het idee is dan dat een AI-systeem in staat is om aan de hand van een MRI-foto een beginnende tumor te detecteren.
Allereerst zijn daar veel MRI’s van hersenen voor nodig – scans van hersenen met en zonder tumoren. Hoe kom je aan zo veel (of genoeg) materiaal? Wie bereidt dat materiaal voor, wie markeert de kenmerken van beginnende tumoren zodat de machine ervan kan leren, hoe zorgen we ervoor dat de input betrouwbaar is? Voor medische toepassingen is het bijvoorbeeld cruciaal dat de data beoordeeld worden door experts – en niet door microwerkers die geen medische kennis hebben. Hoe krijg je dat voor elkaar?
Door de hele pijplijn stroomt de dataset die gebruikt wordt, legt Luitse uit, en die bepaalt bijna alles in medisch AI-onderzoek: wat er onderzocht kan worden, welke technieken kunnen worden toegepast en uiteindelijk welke toepassingen er mogelijk zijn in de praktijk. Wie AI-onderzoek wil doorgronden, dient daarom de dataset te doorgronden.
En dat is om nog een reden cruciaal, legt Luitse uit. Veel datasets kennen zogenoemde ‘biases’, vooroordelen, doordat zij niet bestaan uit data van een diverse groep patiënten. Dit heeft consequenties voor de uiteindelijke toepassingen. Luitse: ‘Als bijvoorbeeld een AI-toepassing voor de detectie van huidkanker is getraind op een dataset van met name witte huidtypes van patiënten uit West-Europese ziekenhuizen,* dan is die niet automatisch toe te passen in ziekenhuizen in Noord-Amerika, Latijns-Amerika of Afrikaanse landen.’
Die biases in de data zijn voor de promovenda een belangrijke reden om dit onderzoek te doen. ‘Het tegengaan van die biases is een van de grote uitdagingen om kunstmatige intelligentie te ontwikkelen in de gezondheidszorg’, zegt ze. ‘Inzicht in de pijplijn kan bijdragen aan het ontdekken en het verhelpen van biases die ontstaan in verschillende stadia van het productieproces.’
Wedstrijden voor het volgende wondermiddel
Een fascinerend onderdeel van de pijplijn zijn AI-competities. Luitse deed samen met twee andere onderzoekers onderzoek naar deze wedstrijden die op meerdere sites worden uitgeschreven voor specifieke onderzoeksproblemen. Bijvoorbeeld voor het detecteren van een hersentumor. Onderzoeksteams kunnen meedoen aan die wedstrijd en concurreren met elkaar. Zij ontwikkelen hun eigen modellen, passen die toe op een dataset en het team dat het hoogst scoort, wint de wedstrijd – en daarmee vaak een geldbedrag.
Luitse en haar co-auteurs beschrijven in een nog niet gepubliceerd paper de invloed van de partijen achter deze wedstrijden. Zij bepalen waar onderzoek naar wordt gedaan, wat de spelregels van de wedstrijden zijn en de ‘winnende’ modellen hebben een grotere kans om in het ziekenhuis toegepast te worden. Ze hebben, kortom, grote invloed op voor welke aandoeningen er modellen worden ontwikkeld en welke data er gebruikt worden voor het trainen en testen van deze modellen.
Alleen als je het hele proces snapt, kun je verbeteringen aanbrengen
Dat is interessant om te weten, maar gaat het er uiteindelijk niet gewoon om of zo’n applicatie werkt? Detecteert kunstmatige intelligentie eerder of beter kanker? Is ze in staat om het leven van patiënten op de intensive care te verbeteren?
De huidige hype kan ertoe leiden dat mensen niet inzien dat er nog een flinke weg te gaan is
Juist omdat er nu met zo veel toepassingen wordt geëxperimenteerd, is begrip van het complete proces cruciaal, legt Luitse uit. Want medische AI werkt nog lang niet perfect, en dan wil je wel weten hoe de toepassing tot stand is gekomen: waar en door wie precies het onderzoek is gedaan, welke data zijn gebruikt, en welke partijen daarbij betrokken waren. Alleen dan kun je problemen zoals biases opmerken – en bedenken of er een oplossing voor bestaat.
‘Het is een ontzettend complex proces om in kaart brengen’, legt Luitse uit. ‘De huidige hype over pasklare en niet-medische AI-toepassingen kan ertoe leiden dat mensen niet inzien dat er nog een flinke weg te gaan is. Bij generatieve AI zoals ChatGPT of DALL-E zijn de implicaties van een feitelijk onjuiste zin of een afbeelding met een extra vinger niet levensbedreigend. Bij medische toepassingen wil je dat alles klopt. Die perfectie kun je alleen benaderen door de hele pijplijn in acht te nemen.’
Waarom we politiek niet alleen aan politici kunnen overlaten
Eva RoversHet beste antwoord op autocratie? Meer democratie. Eva Rovers laat zien hoe we onze democratie kunnen versterken.
