Zo heb ik de 1,2 miljoen tweets verzameld en geanalyseerd

Voor het verhaal over de Twitteroorlog heb ik veel data gebruikt. In dit stuk licht ik bij wijze van journalistieke verantwoording toe hoe ik dat heb gedaan en welke keuzes ik daarbij heb gemaakt.
Het voordeel van een online ruzie is dat er heel veel datasporen zijn om te volgen. Toen het idee ontstond om een verhaal te maken over Jelmergate en de verziekte verhoudingen op Twitter, heb ik aangeklopt bij socialmediabedrijf Coosto. Zij hebben een Nederlands socialmedia-archief en verkopen die data aan bedrijven en instanties. Ik heb als correspondent eenmalig toegang gekocht tot dit archief.
Vervolgens heb ik eerst handmatig bekeken wie er bij Jelmergate betrokken waren en vervolgens alle tweets (1,2 miljoen) die ze sinds 1 januari 2009 hebben verstuurd in een database opgeslagen. Hieruit kon ik tweet voor tweet Jelmergate reconstrueren. Wie zei wat, tegen wie en wanneer?
Uit ruim 780.000 tweets heb ik een sociaal netwerk kunnen reconstrueren
Maar de echt interessante inzichten zitten niet in de inhoud, maar in de metadata: dus wie met wie communiceert. Ik heb de tweets eruit gefilterd die niet onderdeel waren van een gesprek: bijvoorbeeld als iemand een tip aan al zijn volgers stuurt. Ik hield ruim 780.000 tweets over.
Uit deze data kun je een sociaal netwerk reconstrueren. Daarvoor heb ik het programma Gephi gebruikt. Omdat er bijna dertigduizend verschillende twitteraars in het overzicht zaten, werd de visualisatie te gecompliceerd. Ik heb daarom gefilterd op twitteraars die vaker dan honderd keer bij een gesprek waren betrokken. Met het zogenoemde Fruchterman-Reingold-algoritme heb ik het daadwerkelijke netwerk geconstrueerd.
Als twitteraars veel met elkaar praten, zitten ze dichter bij elkaar. Je krijgt met zo’n netwerk dus een soort landschap van waar twitteraars staan ten opzichte van elkaar. Zo’n netwerk ziet er als volgt uit:
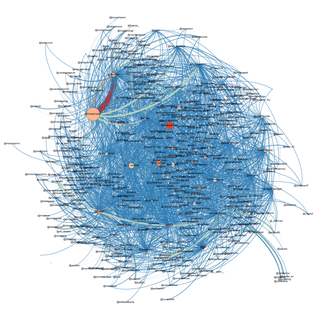
Hier kun je nog niet zoveel mee. Door met opmaak te spelen en een aantal filters toe te passen, kwam ik op deze indeling. Er zitten nog wat verdwaalde mensen tussen, die niet netjes in de groep passen waar ze zijn terechtgekomen. Het feit dat iemand dicht tegen iemand aanschurkt, hoeft ook niet te betekenen dat de twee het goed kunnen vinden. Het kan ook zijn dat iemand simpelweg vaak wordt genoemd in tweets, bijvoorbeeld omdat die persoon zichtbaar is in de media.
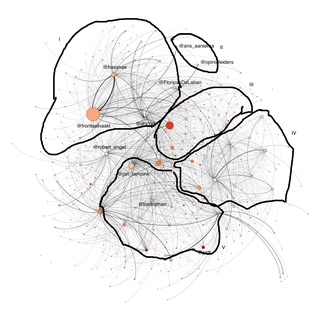
Tot slot wil ik toch nog een beetje speculeren, want je kunt veel meer uit deze data halen. Het Amerikaanse onderzoeksinstituut Pew Internet bijvoorbeeld deed vorig jaar interessant onderzoek naar de structuur van conversaties op Twitter. Het ontdekte dat als je op deze manier gesprekken visualiseert, je per onderwerp verschillende netwerkstructuren ziet. Een politieke discussie (in de Verenigde Staten) laat bijvoorbeeld een gepolariseerde netwerkstructuur zien. Er zijn twee grote clusters: een Democratische en een Republikeinse, met daartussen weinig verbindingen. In het netwerk praat iedereen met zijn eigen groep. Ik had van tevoren zo’n gepolariseerde structuur verwacht.
De ruzies in de Nederlandse Twittersphere zijn eveneens zeer ideologisch geladen. Ik vond echter een andere structuur, eentje waarbij iedereen met iedereen lijkt te praten. Dit soort structuren passen, volgens Pew Internet, bij een heel ander soort gesprek: dat van fans, mensen met een gezamenlijke liefhebberij.
Vanwege de beperkte hoeveelheid data (en vooral de bias die in de selectie van de tweets zit) durf ik deze conclusie niet heel hard te brengen, maar ik vind haar opvallend genoeg om toch nog even te melden. Het zou namelijk betekenen dat veel Twitteraars er ook een sardonisch genoegen in scheppen om elkaar zo de tent uit te vechten.
Wil je meer over dit soort netwerkanalyses weten, lees dan ook deze verhalen:
Word boekenlid van De Correspondent
Ontvang al onze nieuwe boeken automatisch in huis – en maak het volgende verrassende boek mogelijk.
